
系统工程的聚类分析法
时间:2024-09-27 来源:网络 人气:
引言
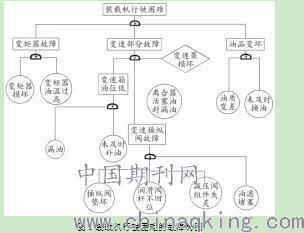
聚类分析法的定义与原理
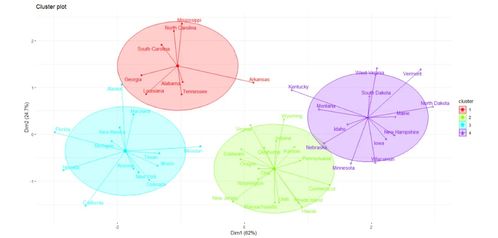
聚类分析法(Cluster Analysis)是一种无监督学习的方法,它将相似的数据点归为一类,从而形成多个簇(Cluster)。每个簇内部的成员具有较高的相似度,而不同簇之间的成员则具有较低的相似度。聚类分析法的基本原理是通过计算数据点之间的相似度,然后根据相似度将数据点分组。
聚类分析法的原理可以概括为以下几个步骤:
选择合适的相似度度量方法,如欧氏距离、曼哈顿距离等。
计算数据点之间的相似度,形成相似度矩阵。
根据相似度矩阵,选择聚类算法,如K-means、层次聚类等。
执行聚类算法,将数据点分配到不同的簇中。
评估聚类结果,如轮廓系数、Calinski-Harabasz指数等。
聚类分析法的应用场景
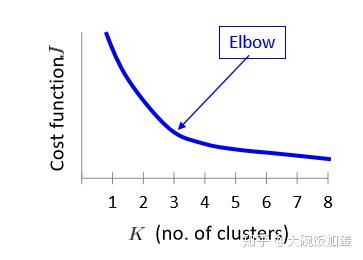
需求分析:通过对用户需求的聚类,可以发现不同用户群体的共性,从而更好地满足用户需求。
系统设计:在系统设计阶段,可以通过聚类分析识别出系统中的关键组件,优化系统结构。
风险评估:在风险评估过程中,聚类分析法可以帮助识别出潜在的风险因素,提高风险管理的有效性。
性能优化:通过对系统性能数据的聚类分析,可以发现系统性能的瓶颈,从而进行针对性的优化。
常见的聚类算法

在系统工程中,常用的聚类算法包括以下几种:
K-means算法:K-means算法是一种基于距离的聚类算法,它通过迭代优化聚类中心,将数据点分配到最近的聚类中心所在的簇中。
层次聚类算法:层次聚类算法是一种基于层次结构的聚类算法,它通过合并相似度较高的簇,逐步形成层次结构。
密度聚类算法:密度聚类算法,如DBSCAN(Density-Based Spatial Clustering of Applications with Noise),通过识别高密度区域来形成簇。
聚类分析法的注意事项

在使用聚类分析法时,需要注意以下几点:
数据预处理:在聚类分析之前,需要对数据进行清洗、标准化等预处理操作,以确保数据的准确性和一致性。
聚类算法的选择:不同的聚类算法适用于不同类型的数据和场景,需要根据实际情况选择合适的算法。
聚类结果的解释:聚类结果需要结合实际背景进行解释,避免误判和误导。
结论
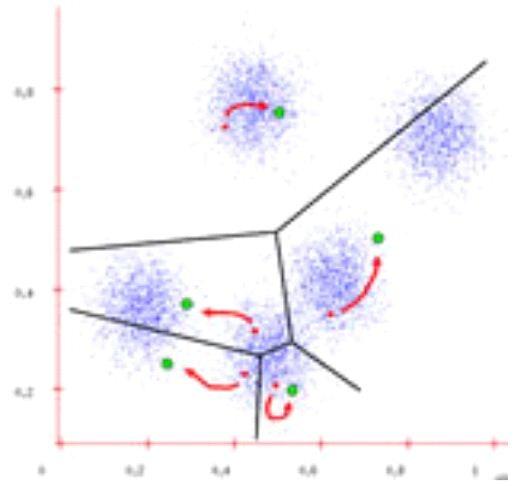
系统工程 聚类分析法 数据分析 K-means 层次聚类 密度聚类 模型聚类 数据预处理 相似度度量
相关推荐




教程资讯
教程资讯排行









